我们为什么要了解这些过程?
只有了解了浏览器的加载、解析、渲染过程,才会知道为什么 js 脚本要写在页面的最下面,才会知道如何构建 dom 结构才能在最短的时间解析完成。
浏览器的主要功能
浏览器的主要功能是将用户选择的web资源呈现出来,它需要从服务器请求资源,并将其显示在浏览器窗口中,资源的格式通常是HTML,也包括PDF、image及其他格式。用户用URI(Uniform Resource Identifier统一资源标识符)来指定所请求资源的位置。
这些年来,浏览器厂商纷纷开发自己的扩展,对规范的遵循并不完善,这为web开发者带来了严重的兼容性问题。
浏览器的构成
用户界面、浏览器引擎、渲染引擎、网络、UI后端、JS解释器、数据存储
要注意的是,不同于大部分浏览器,Chrome为每个Tab分配了各自的渲染引擎实例,每个Tab就是一个独立的进程。
浏览器加载
当我们在浏览器的输入框输入一个网址,会发生什么呢?
- 输入网址
- 浏览器查找域名的 IP 地址
- 浏览器给 web 服务器发送一个 HTTP 请求
- 网站服务的永久重定向响应
- 浏览器跟踪重定向地址并发送另一个获取请求
- 服务器接收到获取请求,然后处理并返回一个响应
- 服务器发回一个HTML响应
- 浏览器开始加载解析HTML
当然,我们现在的网页都包含大量的图片、css、js等资源文件,使页面的显示更优雅。
js 脚本
web 的模式是同步的,开发者希望解析到一个script标签时立即解析执行脚本,并阻塞文档的解析直到脚本执行完。如果脚本是外引的,则网络必须先请求到这个资源——这个过程也是同步的,会阻塞文档的解析直到资源被请求到。这个模式保持了很多年,并且在html4及html5中都特别指定了。开发者可以将脚本标识为defer,以使其不阻塞文档解析,并在文档解析结束后执行。
css 样式表
样式表采用另一种不同的模式。理论上,既然样式表不改变Dom树,也就没有必要停下文档的解析等待它们,然而,存在一个问题,js 脚本可能会获取 dom 的样式,如果样式还没有加载解析完成,那么脚本可能会获取到错误的信息,展示的内容可能会和预想的结果有很大的偏差。这看起来是个边缘情况,但确实很常见。Firefox在存在样式表还在加载和解析时阻塞所有的脚本,而Chrome只在当脚本试图访问某些可能被未加载的样式表所影响的特定的样式属性时才阻塞这些脚本。
当然,现在的浏览器支持页面资源预加载(prefetch),会预先下载页面所需要的js、css等文件。不过,真正的执行过程还是在其原来的位置。
因此,可以使用预加载来提前加载资源文件
<link rel="prefetch" href="http://css.css" />
使用 defer 属性异步加载js
<script defer="true" src="JavaScript.js" type="text/javascript"/>
使用 script 操作dom来动态加载js
function loadScript(url, callback){
var script = document.createElement('script');
script.type = 'text/javascript';
if(script.readyState){ //IE下
script.onreadystatechange = function(){
if(script.readyState == 'loaded' || script.readyState == 'complete'){
script.onreadystatechange = null;
callback();
}
}
}else{ //其他浏览器
script.onload = function(){
callback();
}
}
script.src = url;
document.getElementsByTagName('head')[0].appendChild(script);
}
浏览器渲染
渲染引擎的目的就是呈现出浏览器请求到的数据,每个浏览器都有自己的渲染引擎。目前,Firefox 使用的是 Gecko,Safari 和 Chrome 浏览器使用的都是 WebKit,IE不想用。
下面是渲染引擎的基本流程:

浏览器解析 html 文档,并将里面的各个tag转化成 dom 树上的节点,同时解析 css 样式形成 render 树。
render 树上面会包含有一些样式属性的节点,排序顺序就是它们在屏幕上展示的顺序。
当两棵树构建完成,进入布局阶段,浏览器会为每个节点分配它在浏览器上的确切坐标。
下一个阶段是绘制阶段,浏览器的渲染引擎会遍历 render 树,并将每个节点绘制出来。
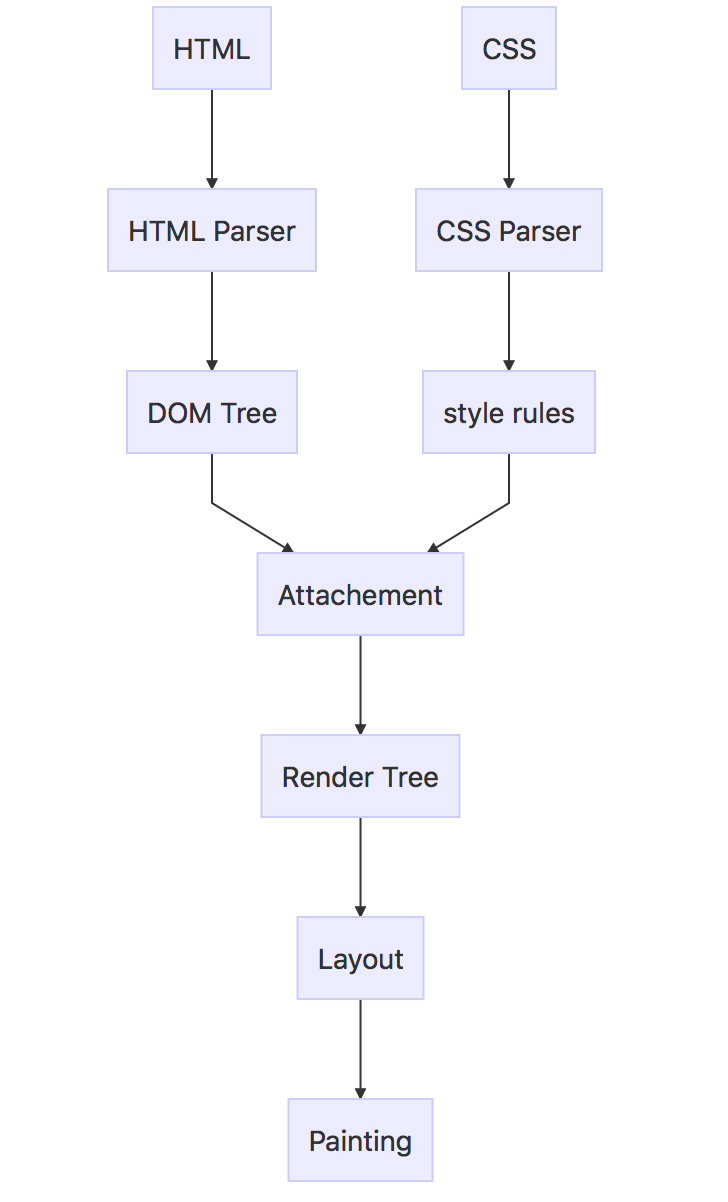
需要注意的是,为了更好的用户体验,渲染引擎会尽早将内容显示在屏幕上,并不会等到所有的 html 都解析完成之后再去构建和布局 render 树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
浏览器解析
解析是渲染过程中非常重要的一环。
html 解析
HTML的解析分为两个过程,词法解析和语法解析。词法分析就是将输入分解为符号,符号是语言的词汇表。语法分析指对语言应用语法规则。
<html>
<body>
<p>Hello World</p>
<div>
<img src="example.png"/>
</div>
</body>
</html>
可翻译成如下的 DOM 树:
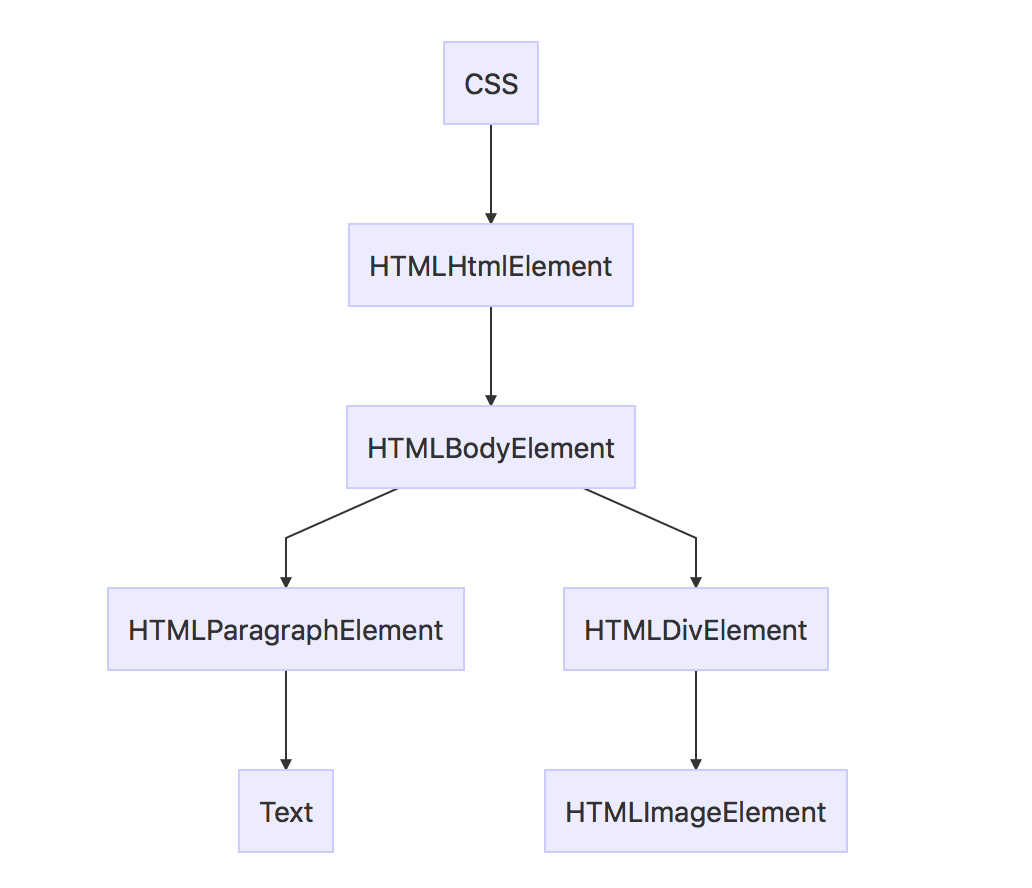
我们在浏览html网页时从来不会遇到 「语法错误」 的情况,因为浏览器具有一定的容错机制,会纠正无效的内容。但是,在书写 html 代码时最好不要有错误的写法。
css 解析
CSS 是上下文无关的语法,可以使用简介中描述的各种解析器进行解析。事实上,CSS 规范定义了 CSS 的词法和语法。
p, div {
margin-top: 3px;
}
error {
color: red;
}
上面这段 css 代码将会解析成如下规则:
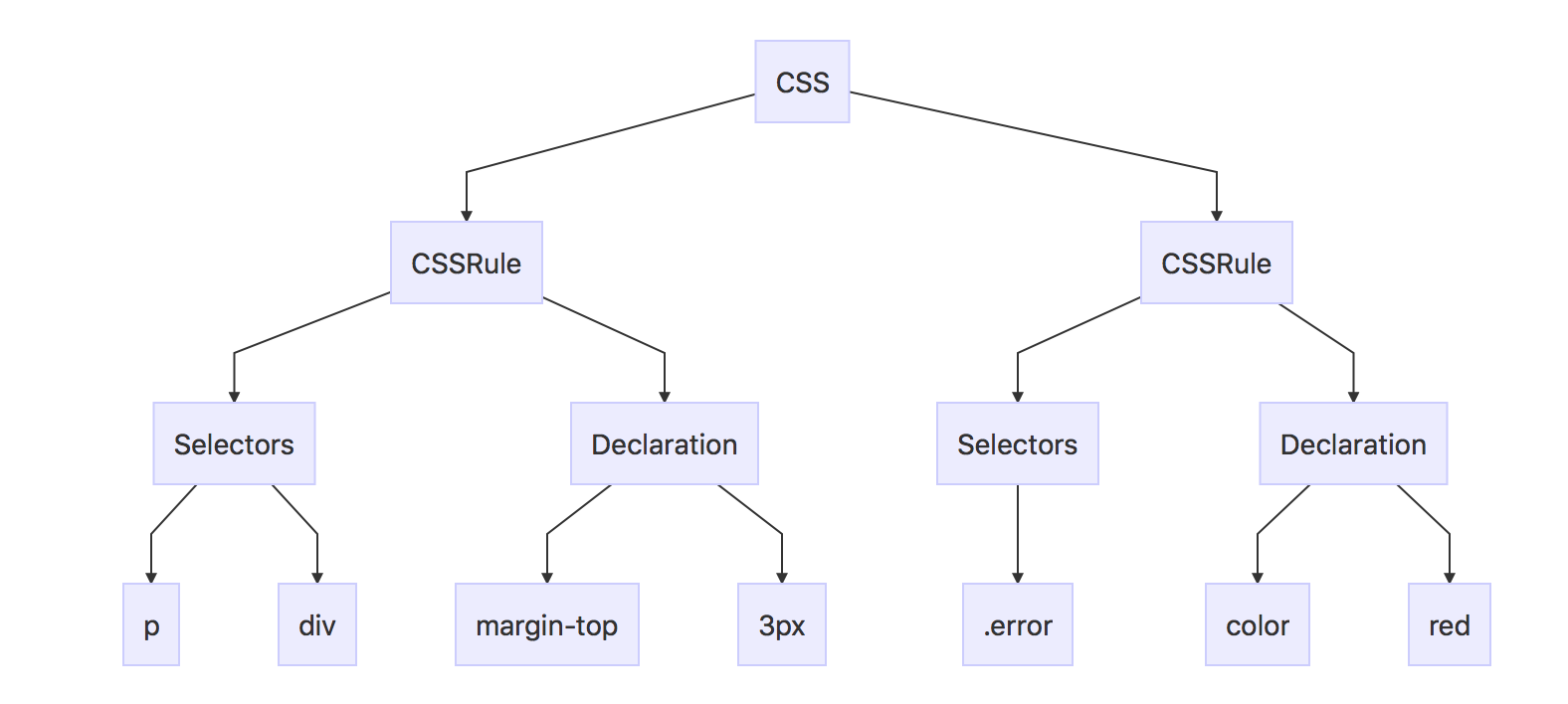
css 的匹配是从左到右的匹配,如果换成从右到左,那么就要找到最顶层的元素,依次向下寻找,如果都不匹配要回到最顶层元素,换另一条路继续匹配,这样需要回溯若干次才能确定是否匹配成功。如果采用从左到右匹配规则,在匹配的第一时间就可以排除一大部分元素。
根据匹配规则,在书写 css 时要尽量做到高效匹配:
1、不要在ID选择器前使用标签名
div#divBox
因为 id 选择器是唯一的,加上前面的标签名反而增加了不必要的匹配。
2、尽量不要在 class 选择器前使用标签名
3、尽量少使用层级关系
#div #span.red{color:red;}
4、id 和 class 之间的效率差距并不大。不过 css 的语义化可以参考下面的文章。
本文参考文章: